
SALUD
Descifrando al enemigo: así se hace la secuenciación del covid-19 en Colombia
SEMANA visitó el laboratorio donde fue secuenciado el primer genoma del coronavirus del país. Sus científicos explican por qué este proceso es clave a nivel mundial.
Encuentra aquí lo último en Semana
En la lucha mundial por acorralar al nuevo coronavirus hay diferentes frentes. Están quienes arriesgan su vida en los hospitales, los que salen a las calles a seguirle la pista al virus, y aquellos científicos que intentan decodificar los detalles de este enemigo mortal, en los laboratorios.
Dentro de este último grupo está el equipo de Virología de la Unidad de Secuenciación y Genómica del Instituto Nacional de Salud (INS), que hace unas semanas logró secuenciar el primer genoma completo del covid-19 en el país. El hallazgo dio las primeras luces sobre cómo llegó el virus a Colombia.
Detrás de la hazaña están cuatro jóvenes que no superan los 34 años y conformaron este equipo de forma relámpago. Según explica a SEMANA Marcela Mercado, directora de investigaciones del INS, “la unidad nació a mediados de enero por la necesidad de entender qué estaba pasando al otro lado del mundo con el virus en cuanto a secuencias y protocolos de diagnóstico”.
En ese sentido, el primer trabajo del grupo fue seleccionar la mejor prueba para el país, guiándose a través de ensayos en computador y softwares especiales. De ahí que hoy el país utilice para el diagnóstico de casos la Prueba Molecular en tiempo real (PCR) y los protocolos de Berlín, recomendados por la Organización de la Salud Mundial (OMS).
La tarea de este pequeño grupo de biólogos, virólogos y bacteriólogos, es secuenciar la mayor cantidad posible de cepas en pacientes colombianos para que científicos de otras áreas, reconstruyan con precisión la manera en la que actúa en el país. “Entre mayor información obtengamos, se puede hacer una predicción más precisa”, dice el biólogo Carlos Álvarez y quien hace parte de la Unidad.
Realizar la secuenciación de un genoma es un proceso complejo y dispendioso. Este nuevo virus tiene alrededor de 29.900 pares de letras y para armar ese rompecabezas, una simple muestra debe pasar por varios procesos de laboratorio. Para empezar, "requiere la extracción del ARN de una muestra del paciente positivo; luego una conversión química a través del proceso llamado retrotranscripción, para que pueda ser secuenciado en los equipos; y de ahí pasa a un proceso de amplificación y ensamble donde se juntan cada una de estas piezas" explica Nicolás Franco, biólogo del Instituto Humboldt y quien participó en el trabajo.

En una etapa posterior, estos genomas aislados pasan por análisis bioinformáticos y filogenéticos que dan información sobre el contexto evolutivo y la tasa de mutación del virus. Este proceso genera tales detalles que, según el biólogo Carlos Franco, permite entender su procedencia, cómo se relaciona con otras cepas reportadas a nivel mundial y hasta cadenas de transmisión desconocidas.
“Hay muchos pacientes en Colombia de los cuales se desconoce su origen del contagio, con esta información podemos reconstruir la historia que se perdió y saber dónde pudo infectarse”, afirma.
La secuenciación de un genoma puede tardar hasta tres días, en contraste con el proceso diagnóstico donde el análisis de 100 muestras de forma simultánea requiere tres o cuatro horas. Por eso, hay que ser selectivos a la hora de decidir qué muestran pasan por este análisis.
“No todas las 52 mil que hemos hecho hasta ahora entran a secuenciación porque es un proceso muy costoso y exclusivo. Se mapean los casos y dada su importancia en la dinámica de la epidemia, las seleccionamos. Inicialmente escogimos viajeros para saber de dónde venía el virus. Ahora, estamos escogiendo contactos de viajeros y después analizaremos personas de la comunidad”, anticipa Mercado.
Los hallazgos
Para el caso de Colombia, las dos primeras secuencias registradas hasta ahora en la base de datos mundial del Sars-Cov-2 corresponden a un paciente antioqueño y otro bogotano. Con ambas, los investigadores establecieron que el virus llegó al país el pasado 26 de febrero de 2020 y pertenecen a dos cadenas de transmisión: una de España y otra de Italia.
“Los denominamos linaje A y linaje B. En el linaje A1, del paciente de Antioquia, vemos secuencias reportadas en Tasca, Chile y Castilla, España. Esta corresponde a un sublinaje denominado A5. En el genoma del paciente de Bogotá encontramos uno totalmente diferente, denominado B1. Este sublinaje contiene secuencias de 20 países que tuvieron casos importados de la gran ola de Italia”, explica la bacterióloga Katherine Laiton.
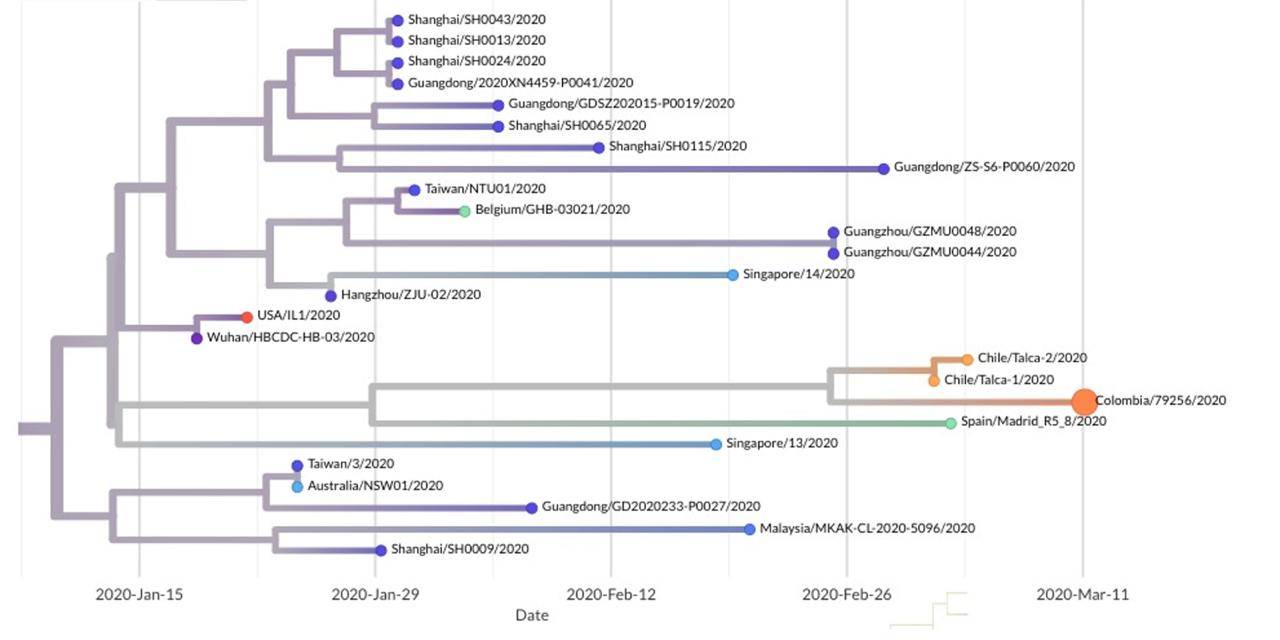
Hasta este momento, estos dos linajes no reportan una mutación que implique más severidad o mortalidad de los pacientes, pero los expertos advierten que deben seguir evaluando sus cambios.
El biólogo Carlos Franco explica que, la alteración del ARN en estos microorganismos es normal pues cada vez que salta de una persona a otra, o se propaga en un mismo cuerpo, el virus se copia a sí mismo y genera errores. “Pero eso no quiere decir que sea más o menos agresivo. Es un proceso natural”.
Seguir decifrando la estructura genética de los virus en el país resulta clave para enfrentar al enemigo: ayudan a refinar los métodos de diagnostico, el diseño racional de estrategias, pero también, son el insumo principal para que los laboratorios de todo el mundo desarrollen vacunas o pruebas de anticuerpos. Por eso, el grupo de secuenciación del INS ya tiene listo el análisis de nueve cepas más para liberar, y el plan es seguir aumentando el número.
Trabajo mundial
Los datos producidos por estos colombianos también tienen un impacto mundial. Suman un grano de arena a la iniciativa de trazar el árbol genealógico del virus desde su aparición en Wuhan. Gracias a la colaboración desinteresada de muchos científicos, que hoy comparten las secuencias en una plataforma online ( NextStrain), el mundo ha conocido en tiempo récord cómo se propaga el nuevo coronavirus.
Desde que China reportó el primer caso a la Organización Mundial de la Salud (OMS) en diciembre de 2019, pasaron dos semanas para que los científicos aislaran el virus y descubrieran la secuencia completa de su material genético. Y tan pronto como esa información fue pública, las compañías de biotecnología comenzaron a crear copias sintéticas del virus para iniciar la investigación.
Todo esto sucedió más rápido que nunca gracias al avance de la tecnología y el intercambio de datos. En menos de cuatro meses la ciencia ha logrado secuenciar alrededor de 3.000 genomas del coronavirus en todo el mundo, y el pasado 9 de abril la revista Proceedings of the National Academy of Sciences (PNAS) publicó un estudio que asegura que hay tres variantes distintas de virus circulando, desde que surgió la enfermedad en Wuhan.

Apodados como A, B y C, estos tres tipos de Sars-Cov-2, han seguido diferentes caminos. Posiblemente porque han mutado para infectar mejor a poblaciones específicas.
Según los investigadores de la Universidad de Cambridge, la variante A es la cepa ancestral y está más estrechamente relacionada que el resto con el coronavirus que se encuentra en los murciélagos y los pangolines. Los científicos creen que la enfermedad saltó a los humanos de una de las criaturas en el mercado de Wuhan, pero sorprendentemente no es el tipo de virus predominante en la ciudad.
El virus que más circula en Wuhan es el B y de acuerdo a los investigadores prevalece en pacientes de todo el este de Asia. Sin embargo, la variante no viajó mucho más allá de la región. Esto indica, según los investigadores, que algún factor aún desconocido en Wuhan lo hizo mutar, o que fuera de Asia existe una resistencia biológica contra este tipo de covid-19. Esta versión del virus se deriva de A y está dividida en dos linajes más en el mundo.
La última de las cepas es C, hija de B. Es el virus que predomina en los primeros pacientes de Francia, Italia y Gran Bretaña, pero no se encuentra en China. Curiosamente los científicos sí la han identificado en Singapur, Hong Kong y Corea del Sur.
El nuevo análisis también sugiere que una de las primeras introducciones del virus en Italia se produjo a través de la primera infección en Alemania, documentada el 27 de enero. Otra ruta temprana de infección en este país también se relacionó con un grupo de Singapur. El trabajo fue hecho con los primeros 160 genomas secuenciados del virus en pacientes humanos y utilizó datos muestreados de todo el mundo entre el 24 de diciembre de 2019 y el 4 de marzo de 2020.
Los tiempos en que se lograron estos hallazgos son récord si se comparan con los del brote del Sars en 2002. Pasaron meses antes de que el genoma viral fuera secuenciado y aún más para que fuera copiado en un laboratorio. Esta velocidad es de vida o muerte en una pandemia, más aún cuando el nuevo coronavirus dista de todo lo que los expertos en salud pública habían visto antes.

También influye que acceder a esta tecnología hoy es mucho más barato que hace dos décadas. Por poner un ejemplo: si entonces hacer una copia sintética de un solo nucleótido (el componente básico del material genético) costaba 10 pesos, ahora ese precio es menor a 1. Teniendo en cuenta que el gen de coronavirus tiene alrededor de 30.000 nucleótidos, el costo marca una gran diferencia en cuántas copias pueden hacer los científicos, incluyendo a Colombia.
Queda mucho por conocer
A pesar de la rapidez con la que se ha construído el mapa de contagio aún quedan muchos interrogantes por resolver. Por eso, desde la dirección de Investigación del Instituto Nacional de Salud, los científicos adelantan trabajos en diferentes frentes. Según Mercado, está en marcha un proyecto de infección por covid-19 en trabajadores de la salud y otras áreas en constante contacto con personas, que lidera el grupo de Salud Ambiental y Laboral del Instituto. También otro sobre pacientes con cero prevalencia, que “servirá para determinar la proporción de personas que van a quedar inmunes después de la epidemia o susceptibles”, explica.
A esto se suman dos proyectos de investigación genómica: uno que buscará cultivar el virus en laboratorios del país, y otro, cuyo objetivo será desarrollar una prueba diagnóstica propia. “Queremos una prueba serológica made in Colombia y para eso se necesita cultivar el virus, hacer análisis de neutralización y probarlas a partir de productos elaborados por nosotros”, agrega Mercado. Varios de estos trabajos son colaborativos con Universidades y laboratorios, y están realizándose con pacientes hospitalizados y en cuidados intensivos que permitan describir mejor la dinámica del virus en país.
Hasta ahora el único que ha mostrado un resultado concreto ha sido el de la primera secuenciación del coronavirus, pero todos tienen el desafío de entregar resultados rápidos debido a la urgencia mundial. “Estamos recolectando muestras, haciendo trabajo en campo y afinando protocolos de investigación para que la información salgo pronto”, asegura Marcelo.
Para este grupo de científicos la secuenciación del virus será aún más importante a medida que el mundo empiece a superar la epidemia, pues este trabajo, muchas veces invisible, permitirá saber cuántas cadenas de transmisión del covid-19 siguen circulando en el país y por qué zonas. Igual como hoy se hace con el zika, el ébola y el dengue.
“Lo que reportamos en Colombia apenas es un genoma, pero para llegar a una conclusión más precisa sobre cómo nos afectó y afectará se necesita acumular información de cientos de genomas más”, concluye el biólogo Diego Álvarez.
*Periodista de Vida Moderna